YARN Log Aggregation (日志聚合) 不完全指南
本文主要取材并翻译自Deep dive into YARN Log Aggregation,并结合了一些个人理解。本文假设读者对于YARN有基本的了解。
简介
YARN 及启动的容器会不断地产生应用日志,取决于工作负载的类型,这些日志或大或小。YARN 日志通常会消耗宝贵的磁盘空间,尽管可以通过压缩和归档在一定程度上缓解,大多数日志在平时也不会那么有用,但是当任务发生错误时,日志是排查错误的最佳手段。
YARN 的 NM 负责实际的应用负载,意即负责实际的 container 运行。日志也是由这些 container 产生,并存储在 NM 的本地路径上。在默认情况下,应用结束时,日志会被保留一段时间后删除。但是,因为一个应用可能会有多个 container,它们可能会横跨许多 NM,因此日志排查有一定的困难。因此,YARN 提供了日志聚合功能,使得应用产生的日志文件可以以一定策略上传到 HDFS 或基于云的存储。这使得日志的存储时间比在本地磁盘上要长得多,可以更快地搜索特定的日志文件,并且可以选择处理压缩。
名词解释
- Application Master:YARN 应用的第一个容器,向RM发送容器请求,并负责请求/释放容器资源。所有YARN应用必须拥有一个AM。
- 日志聚合(Log aggregation):创建一个单一聚合日志文件的行为,该文件由YARN应用容器创建的多个文件组成。
- 聚合日志文件(Aggregated log file):一个大文件,它包含了由YARN应用创建的多个日志文件。
- 文件控制器(File controller):负责创建聚合日志文件的Java类。它可能有额外的逻辑(如创建元数据),可以有不同的文件布局。
- 默认模式(Default mode):日志聚合仅在应用结束时发生一次。
- 滚动模式(Rolling mode):日志聚合在YARN应用的生命周期内定期发生,而不是只在其结束时发生。
- 日志聚合策略(Log aggregation policy):决定哪些容器的日志在日志聚合期间被考虑。
- 日志聚合周期(Log aggregation cycle):日志聚合的发生场景。默认模式下仅发生一次,滚动模式下由专门的配置定义。
- 远程日志目录(Remote log directory):上传聚合日志文件的根目录。
架构
生成日志
从Java类中记录日志并不是Hadoop发明的,有多个日志框架都可使用,并且都独立于Hadoop,最流行的选择是Log4j,或者间接说是Slf4j框架。这个日志框架也被YARN的守护程序(RM、NM和历史服务器)所使用。
默认情况下,root logger使用ConsoleOutput appender,它在stdout/stderr中显示Log4j日志条目。YARN自动将这个流重定向到两个文件(stdout和stderr),产生两个后果:
stdout和stderr文件总是被创建。如果应用使用另一种方法进行日志记录,仍会创建stdout和stderr的零字节文件。- 由于Unix和类Unix的操作系统使用文件描述符来识别某个文件或其他输入/输出源,当应用仍在运行时,删除该文件会使文件描述符失效,这意味着不再有日志记录从控制台写入到文件中。
聚集日志
概述
当一个应用的日志被聚合时,RM负责以下任务:
- 组织日志聚合过程
- 处理日志聚合的元数据
- 处理配置,包括策略和控制器配置
- 通过API报告日志聚合的状态
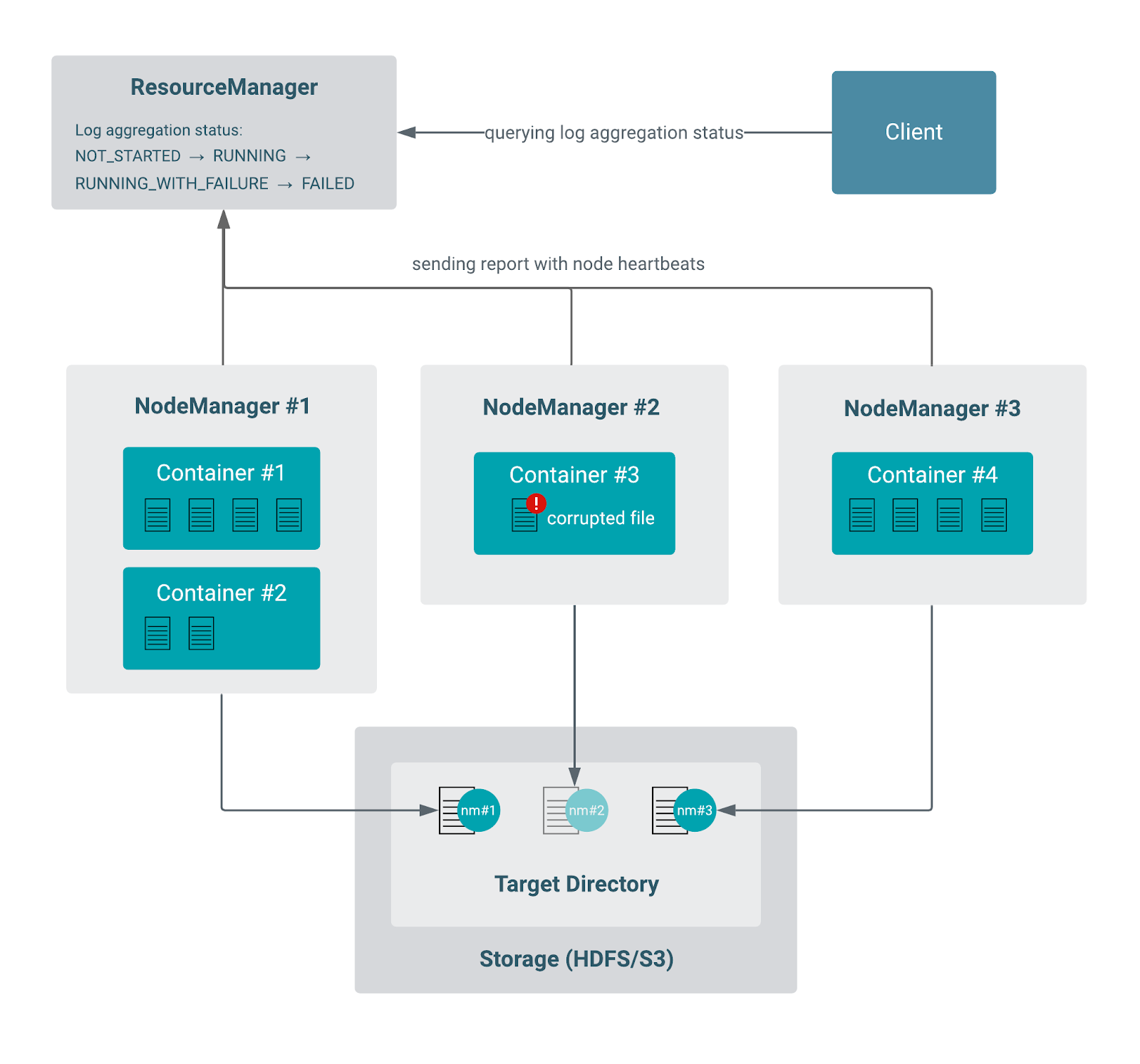
容器属于一个特定的节点,但由于应用通常会启动许多容器,它们可以跨越到多个节点。因此,NM的责任是为该节点上运行应用的容器进行实际的日志收集。节点之间独立地执行这项任务。RM和NM使用心跳机制进行通信,它们使用内部的LogAggregationReport对象来跟踪每个单独节点的聚合状态。
一般步骤
一个日志聚合周期由以下步骤组成:
- 对于每个应用,RM跟踪一个称为日志聚合状态的属性,该属性在整个聚合过程中会更新。
- 日志是在每个节点上聚合的,一个聚合的日志文件由在该特定节点上运行应用的容器产生的所有日志文件组成。
- 聚合的日志文件被上传到一个特定的位置(远程存储)。
- NM定期向RM发送心跳,其中也包括日志聚合报告,通报步骤2和3的状态。
- RM从NM收集所有这些报告,然后将其合并为应用的日志聚合状态。
- 日志聚合状态最终在应用结束时达到一个最终状态(成功、失败或超时)。
更多细节:
- 如果容器还没有完成,其日志的当前内容会被聚合。每个控制器的处理方式不同。
- 每个容器在节点上都有一个专门的目录。这个目录是日志聚合的目标,所以NM将从该目录中收集任何文件(不检查扩展名)。
- 日志是以每个节点为基础进行聚合的,每个节点都有自己的LogAggregator线程。写入和读取日志都是通过LogAggregationController对象进行的。LogAggregationController的责任是封装与这些文件交互的逻辑。
- 即使应用产生的文件是用户可读的,聚合的日志文件也可能包含任意的二进制部分,并可能以复杂的方式进行压缩,这样终端用户就无法将其作为普通的文本文件来使用。相反,用户应该使用YARN CLI来读取日志。
- 某一节点的LogAggregator线程会将该节点上运行的所有容器的日志作为一个聚合文件上传到目标文件系统中。最终,对于单个应用,有多少个属于该应用的运行容器的节点,就会有多少个文件。事实上,一个聚合的日志文件是一组键值对,其中键是日志元数据(文件属性,如名称、大小等),值是文件的内容。
- 应用级的日志聚合状态被初始化为
NOT_STARTED。如果一切顺利,状态会从NOT_STARTED过渡到RUNNING,然后再到SUCCEEDED状态。如果任何一个节点在执行日志聚合时失败了,合并的(应用的)日志聚合状态将变为RUNNING_WITH_FAILURE(尽管只有一次失败,其他节点可以继续进行聚合)。如果所有其他节点都完成了,应用级别的日志聚合状态将是FAILED。默认情况下,RM会在内存中保留10个这样的故障报告。如果节点的日志聚合线程不能及时完成上传,RM将停止等待这些NM,应用的最终日志聚合状态将是TIMED_OUT。
默认模式
- 集群管理员可以在YARN启动前在
yarn-site.xml中指定日志聚合属性。 - 在应用提交时,客户端可以覆盖一些配置的参数,并指定一些额外的参数,如设置策略和文件名包含/排除模式。
- 在应用的AM容器启动后,应用随之启动。
- 当每个容器(包括AM)退出时,应用终止。
- 当所有的容器都结束时,如一般步骤部分所述,会进行一个日志聚合循环。
集群管理员可以指定roll-monitoring-interval-seconds为一个非零值。这个配置控制了NM应该多久唤醒一次,以检查它是否应该上传日志(因为应用已经完成)。这可能会使实际的聚合工作最多延迟roll-monitoring-interval-seconds所表示的时间。
滚动模式
- 集群管理员在YARN启动前在
yarn-site.xml中指定日志聚合属性。管理员必须将roll-monitoring-interval-seconds属性配置为一个非零值以使用滚动模式。 - 在应用提交时,客户端可以覆盖其中的一些参数,并指定一些额外的参数。应用的LogAggregationContext必须包含一个非空的
rolledLogsIncludePattern(可能还有rolledLogsExcludePattern)字段。 - YARN在每一个配置的间隔(用
roll-monitoring-interval-seconds配置属性定义)中执行一个特殊的日志聚合周期,包括以下步骤:- NM检查迄今为止应用的运行或完成的容器产生的每个日志文件。
- 如果任何日志文件的名称与
rolledLogsIncludePattern相匹配,并且与rolledLogsExcludePattern不相匹配,它将被标记为待聚合。 - 选定的日志文件按照一般步骤所述上传(步骤1-5)。
- 一旦所有的容器都完成了,最后的日志聚合周期会被执行,同样如一般步骤所述(步骤1-6)。
根据日志聚合控制器,文件在每个周期中可能被删除,也可能不被删除。如果一个文件被删除,可以在下一个日志聚合周期开始前重新创建,系统能够处理这个问题。新的内容可以附加到以前的聚合日志的末尾,或者作为一个新文件创建。
限制因素
- 由于性能原因,日志聚合状态不会在状态存储或磁盘中持久化。因此,如果应用因RM重启或故障切换而恢复,则日志聚合状态将是
NOT_STARTED,即使是已经完成的应用。 - 日志聚合配置应该在所有NM上相同,否则,一些日志将被聚合到一个单独的远程日志目录。
路径结构
一个节点为每个应用创建一个聚合的日志文件。根据配置,这些日志存储的具体路径可以是不同的。目前有两种日志的路径结构。
新路径结构
日志被聚合到以下路径:<remote-app-log-dir>/<user>/bucket-<suffix>/<bucket id>/<application id>/<NodeManager id>。
路径的前半部分是以如下方式计算的:
- YARN选择文件控制器进行写入,并检索其配置的目录(
yarn.log-aggregation.<file controller name>.remote-app-log-dir)。如果没有指定,它会检查全局配置(yarn.nodemanager.remote-app-log-dir),默认的值是/tmp/logs。 - 类似的机制适用于后缀,但有一点不同:如果没有为控制器定义配置,后缀将默认为
logs-,与用于写入的文件控制器的名称用小写相连接。例如,TFile默认文件控制器的目标目录将是/tmp/logs/<user>/logs-tfile/。
在一个非常大的集群中,可能会遇到这样的限制:有非常多的应用,远程存储无法处理一个单一目录下的子目录数量。出于这个原因,应用被放入桶中,桶名使用其ID除以10000的余数。例如,如果用户 test 启动了三个ID为1、2和3的应用,它们各自的路径将是 /tmp/logs/test/bucket-logs-tfile/0001/app_1/、/tmp/logs/test/bucket-logs-tfile/0002/app_2/ 和 /tmp/logs/test/bucket-logs-tfile/0003/app_3/。
在滚动模式下,根据文件控制器的情况,可以创建一个新的聚合文件。一个时间戳被附加到NM的ID上,以区分在不同周期写入的文件,例如 node-1_8041_1592238362。
传统路径结构
这种结构在后缀和应用ID之间没有目录级别。路径为<remote-app-log-dir>/<user>/<suffix>/<application id>/<NodeManager id>。当一个已经聚合的应用日志的请求到来时,新的路径结构将被检查,但如果没有找到该应用,传统的路径也会被检查。
权限
NM保证远程根日志目录的存在,并且具有正确的权限设置。如果文件夹不存在或存在但有不正确的权限,则在NM的日志中发出警告。
如果创建目录,其的所有者和组将与NM的用户和组相同。该组是可配置的,这在作业历史服务器(简称JHS)在与NM不同的Unix组中运行的情况下是很有用的,这可以防止聚合的日志被删除。
因为每个用户都有自己的目录,用户目录下的目录和文件都以0770的权限创建,只有特定的用户和hadoop组可以访问这些目录和文件。每个单独的聚合日志文件将以0640权限创建,为用户提供rw权限,为hadoop组提供只读权限。由于目录有0770权限,hadoop组的成员将能够删除这些文件,这对自动删除很重要。
获取聚合日志
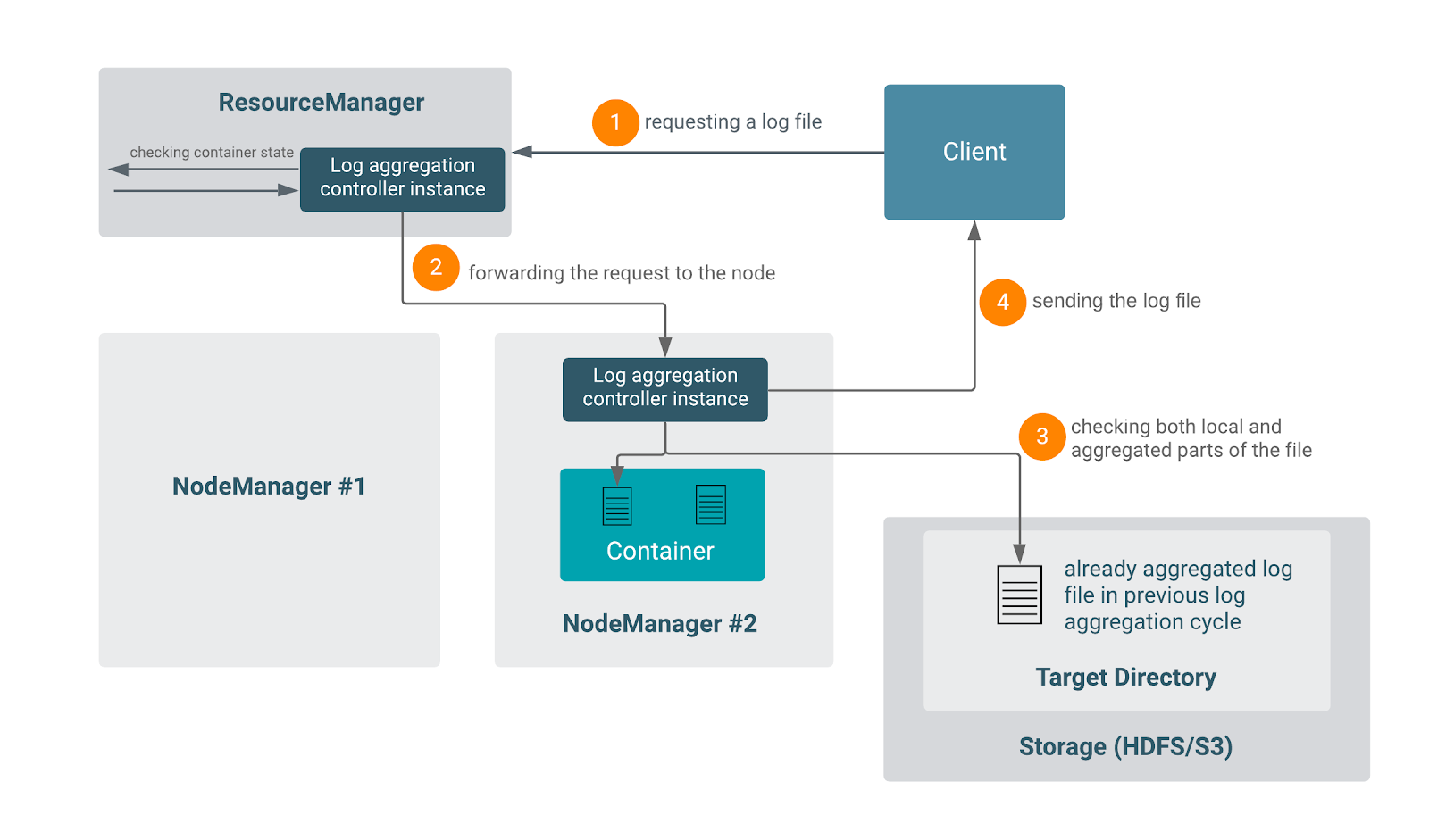
访问聚合日志的推荐方式是它们的编写方式:通过日志聚合控制器的相应Java类访问。不鼓励直接从远程存储中读取聚合日志,因为控制器可能已经在日志文件中写入了额外的二进制字符串,有可能会用户不可读。
虽然实际的Java类只能通过Java兼容的代码来访问,但也有多个端点可以与控制器进行交互。客户端可以使用RM(通过REST API或UI)、YARN日志CLI等内置功能进行访问。
- 控制器从多个地方接受输入(如配置),其中之一是与YARN守护进程共享的
yarn-site.xml。请记住,与守护进程的配置相匹配是至关重要的。 - 另一个输入是参数化的ContainerLogsRequest对象。这个对象已经包含了关于日志去向的所有数据:应用ID、节点ID和地址(如果容器还没有被聚合)、容器的状态等等。
- ContainerLogsRequest对象必须已经被调用者设置了参数,添加了所有必要的信息。一个常见的选择是LogServlet(通过REST API或UI使用)和Logs CLI,但潜在的任何Java代码都能够做到这一点。请记住,调用者必须能够提供容器的最新细节,例如RM确切地知道在哪里可以找到某个容器,而JHS在本地没有这个信息。因此,RM和Timeline Server能够提供每一个细节,以组装一个适当的请求对象。
- 根据应用的状态:
FINISHED:控制器直接读取远程应用的目录。RUNNING:请求被重定向到容器运行的节点,本地NM将处理该请求。NM还与远程存储通信,检查是否有任何包含这个特定容器的日志聚合周期(在滚动模式下)。如果有,就把聚合的部分和本地的部分串联到最终的日志文件中。
目前,不支持访问一个运行中应用的任意完成的容器。只有当用户知道容器的ID并在请求中提供它时才有可能。没有一般的方法来查询一个正在运行的应用的已完成的容器列表。
删除聚合日志
由于历史原因,这个操作是历史服务器的责任,尽管它不符合JHS的其他职责。
它的实现非常简单:有一个定时器线程,定期唤醒并检查所有聚合的日志文件。如果它发现一个文件的时间超过了配置的时间间隔,该文件将被删除。唤醒期和保留超时都是可配置的。如果后者是一个负数,日志删除将被禁用。禁用日志删除是很危险的,需要管理员定期删除汇总的日志文件,以避免填满存储器。JHS必须能够访问聚合的日志文件。
如果日志聚合本身被禁用,聚合日志的删除就会被禁用。如果配置被改变,可以用hsadmin -refreshLogRetentionSettings命令重新配置,而不需要重新启动。
文件控制器
YARN集成了一个日志聚合文件控制器Java类,以便管理和维护日志文件,包括索引、压缩。它可能有额外的逻辑(如创建元数据或索引文件),可以有不同的布局。它们在滚动模式下的行为也可能不同。
该参数可以通过yarn.log-aggregation.file-formats配置,可以配置多项(逗号分隔),但为了向后兼容,建议将 TFile 加入到最后一项。用户也可以添加自己的自定义文件控制器,实现LogAggregationController Java类。
TFile
TFile是YARN中的传统文件控制器,它的缓冲区和块大小是可配置的。主要的功能如下:
- 块压缩
- 命名的元数据块
- 排序或未排序的键
- 按键或按文件偏移量搜索
TFile的内存使用包括一些读取或写入压缩块的恒定开销。此外,每个压缩块都需要一个用于I/O的压缩/解压编码。
从日志聚合的角度来看,TFile的使用方法如下:TFile的键是容器ID,值是属于该容器的日志文件的内容、名称和大小。有一些特殊的保留属性,控制器将其作为文件的键。应用ACL(哪些用户可以查看和修改应用)、应用的所有者、以及格式的布局版本也被放入键值对。
当一个日志聚合周期完成后,TFile不保留本地日志文件,这对那些假定日志文件描述符在其容器的生命周期内受到保护的应用有影响。长时间运行的应用很容易受到影响,应该谨慎地管理日志。当使用滚动模式时,TFile将在每个日志聚合周期创建一个新的聚合文件。
IFile(IndexedFile)
IFile是一个比TFile更新的文件控制器。它也在内部使用TFile,所以提供的功能与TFile相同。
在IFile中,文件是有索引的,所以在聚合的日志文件中搜索要比在普通的TFile中搜索快。它使用校验和和临时文件来防止故障并从故障中恢复。它的缓冲区大小和滚动文件大小可以在TFile的配置选项之上进行配置。
IFile在每个滚动周期中不删除日志文件,因为索引需要原始文件。如果是一个长期运行的应用,在这类应用的生命周期中产生不断增长的日志文件,保留这些文件会可能造成很大的问题。
输入和输出缓冲区的大小可以通过 indexedFile.fs.output.buffer.size 和 indexedFile.fs.input.buffer.size 参数进行配置。另一个值得注意的参数是 indexedFile.log.roll-over.max-file-size-gb,它控制了滚动的大小。如果一个聚合的日志文件在一个日志聚合周期内超过了这个参数的值,就会执行滚动。默认情况下,如果使用滚动模式并且没有达到这个限制,IFile控制器将尝试将新的内容附加到最后一个聚合的日志文件的底部。只有在以上情况,它才会为新的改动创建一个新的文件。此外,还可以配置 indexedFile.fs.op.num-retries 和 indexedFile.fs.retry-interval-ms 属性。
对于 S3 的特殊处理
TFile对任何S3桶都能顺利工作,只要它有正确的凭证。自3.3.0版本以后对IFile也有效。在这之前,可能会遇到错误,需要将 indexedFile.log.roll-over.max-file-size-gb 设置为0,以避免对S3A进行任何追加操作。
配置信息
通用配置
yarn.log-aggregation-enable: 是否开启日志聚合,默认为falseyarn.nodemanager.remote-app-log-dir: 日志聚合的根目录,默认为/tmp/logsyarn.nodemanager.remote-app-log-dir-suffix: 应用的日志聚合目录将会被配置为<remote-app-log-dir>/<user>/<suffix>yarn.nodemanager.log-aggregation.compression-type: TFile 压缩算法,默认为noneyarn.log-aggregation.retain-seconds: 聚合后的日志保留时长,默认-1表示禁用此功能yarn.log-aggregation.retain-check-interval-seconds: 聚合后的日志保留检查间隔时长,如果设置为0或负数,会使用保留时长的1/10来计算
改变日志聚合配置,特别是与路径相关的配置,是不向后兼容的。如果聚合的日志在某个位置,而用户改变了远程应用的日志目录,已经创建的日志将无法使用新的配置进行访问。在这些情况下,建议人工干预,复制或符号连接受影响的目录和文件。
策略配置
日志聚合策略是一个Java类名,它实现了ContainerLogAggregationPolicy。在运行时,如果一个给定的容器的日志应该根据容器类型和其他运行时状态(如退出代码)进行聚合,NM将参考该策略。当应用只想聚集一部分容器的日志时将会很有用。这里列出了可用的策略,请确保在下面的类名前加上org.apache.hadoop.yarn.server.nodemanager.containermanager.logaggregation.来指定规范的名称:
AllContainerLogAggregationPolicy: 聚合所有容器,默认值NoneContainerLogAggregationPolicy: 跳过所有容器AMOrFailedContainerLogAggregationPolicy: 只聚合AM和失败的容器FailedOrKilledContainerLogAggregationPolicy: 只聚合失败和杀死的容器FailedContainerLogAggregationPolicy: 只聚合失败的容器AMOnlyLogAggregationPolicy: 只聚合AM容器SampleContainerLogAggregationPolicy: 聚合AM和失败、杀死的容器,同时对成功的容器进行随机取样
日志聚合策略有一些可选参数。这些是在策略对象初始化时传递给策略类的。一些策略类可能可以使用参数来调整其设置。
控制器配置
yarn.log-aggregation.file-formats: 指定使用哪些日志文件控制器,添加的第一个文件控制器将被用来写入聚合的日志。这个以逗号分隔的配置将与配置yarn.log-aggregation.file-controller.%s.class一起工作,它定义了支持的文件控制器的类。默认情况下,将使用TFile控制器。用户可以通过添加更多的文件控制器来覆盖这个配置。为了支持向后兼容,确保总是添加TFile文件控制器。yarn.log-aggregation.file-controller.%s.class: 支持文件控制器读和写操作的类。文件控制器是由%s定义的。例如:yarn.log-aggregation.file-controller.TFile.class:org.apache.hadoop.yarn.logaggregation.filecontroller.tfile.LogAggregationTFileController。yarn.log-aggregation.%s.remote-app-log-dir: 日志聚合的位置,它覆盖了NM级别的配置yarn.nodemanager.remote-app-log-dir。yarn.log-aggregation.%s.remote-app-log-dir-suffix: 远程日志目录将在<remote-app-log-dir>/<user>/<suffix>创建。它覆盖了NM级别的配置yarn.nodemanager.remote-app-log-dir-suffix。
滚动模式配置
yarn.nodemanager.log-aggregation.roll-monitoring-interval-seconds: NM唤醒上传日志文件的频率,默认值是-1。默认情况下,日志将在应用完成后上传。通过设置该配置,可以在应用运行时定期上传日志。可以通过设置yarn.nodemanager.log-aggregation.roll-monitoring-interval-seconds.min来配置最小可接受值。yarn.nodemanager.log-aggregation.num-log-files-per-app: 在远程文件系统中,每个NM的每个应用可以有多少个聚合的日志文件。默认情况下为30。仅在滚动模式下生效。
细粒度配置
yarn.nodemanager.remote-app-log-dir-include-older: 当日志聚合控制器在远程存储中搜索聚合的日志时,是否也要检查传统的路径结构。默认为true。yarn.log-aggregation-status.time-out.ms: RM等待NM报告其日志聚合状态的时间,默认 600000 (10分钟)。此配置也将在NM中使用,以决定是否以及何时删除缓存的日志聚合状态。yarn.nodemanager.logaggregation.threadpool-size-max: NM中LogAggregationService的线程池大小,默认100。yarn.nodemanager.remote-app-log-dir.groupname: 在Unix系统中,NM将用这个用户组创建远程应用日志目录。- yarn.nodemanager.log.retain-seconds: 保留用户日志的时间,以秒为单位,默认10800 (3小时)。仅在禁用日志聚合的情况下适用。
yarn.resourcemanager.max-log-aggregation-diagnostics-in-memory: 可以保存在RM中的日志聚合诊断/故障信息的数量,它还定义了可以在日志聚合Web UI中显示的诊断/故障消息的数量,默认10。
调试配置
yarn.nodemanager.delete.debug-delay-sec: 在应用结束后,NM的DeletionService将删除应用的本地化文件目录和日志目录之前的保留秒数。为了诊断YARN应用的问题,可以将此属性的值设置得足够大(例如,设置为600),以允许检查这些目录。在改变该属性的值后,必须重新启动NM,以使其生效。yarn.log-aggregation.debug.filesize: 在NM本地目录下创建的日志文件如果超过了配置的字节数 104857600 (100Mb),将被记录下来。这只有在Log4j级别为DEBUG或更低时才会生效。yarn.nodemanager.log-aggregation.roll-monitoring-interval-seconds.min: 定义yarn.nodemanager.log-aggregation.roll-monitoring-interval-seconds的最小硬限制。如果这个配置被设置为小于其默认值(3600),NM可能会发出警告。
其他相关配置
yarn.nodemanager.log-container-debug-info.enabled: 生成关于容器启动的额外日志。目前,这将创建一个启动脚本的副本,并列出容器工作目录的内容。当列出目录内容时,会跟踪符号链接,最大深度为5(包括指向容器工作目录之外的符号链接),这可能会导致启动容器的速度减慢。默认为false。yarn.nodemanager.log.deletion-threads-count: 在NM日志清理中使用的线程数,当日志聚合被禁用时使用。默认为4。
任务提交时配置
LogAggregationContext包括一个应用中可能的选项。在该对象中,用户可以定义一个不同于集群默认的日志聚合策略(由yarn.nodemanager.log-aggregation.policy.class指定)。要覆盖策略类,请定义 policyClassName 属性,而其属性可以通过设置 policyParameters 属性来覆盖。
用户可以提供模式来指定哪些日志文件应该和不应该被聚合,这些模式是正则表达式。如果一个日志文件的名称与includePattern相匹配,它将在应用结束时被上传。同样地,如果匹配excludePattern,它不会在应用结束时被上传。如果日志文件名称同时匹配include和exclude模式,这个文件最终将被排除。
为了使应用在滚动模式下运行,用户应该提供一个rolledLogsIncludePattern,它的工作原理与includePattern类似,如果一个日志文件与定义的模式相匹配,它将以滚动的方式被聚合。它的相反对应是rolledLogsExcludePattern,如果一个日志文件与该模式相匹配,它将不会以滚动的方式被聚合。如果日志文件名与两种模式相匹配,这个文件将最终被排除。
访问日志
远端存储的原始文件
由于聚合的日志存在于远端存储中,用户可以直接访问这些文件。不推荐这样做,主要是因为这些文件包含多个串联的日志文件,可能以复杂的方式进行压缩(无法以常规方式解压),还可能包含日志聚合控制器使用的二进制与非可读部分。读取这些日志文件的推荐方式是使用捆绑在Hadoop中的专用工具之一,如YARN CLI或RM的Web UI。
Logs CLI
有一个命令行界面来访问聚合的日志文件,该工具是高度可配置的:
- 可以检查属于一个容器/应用的聚合文件的列表
- 可以获取日志文件的元数据:
-show_application_log_info: 显示日志被聚合的容器列表-show_container_log_info: 更详细的列表,包括各个日志文件的大小与最后修改时间-list_nodes: 显示成功聚合日志的节点
- 可以获取特定容器的日志:
- 通过
-am获取AM日志 - 通过
-containerId指定container日志
- 通过
- 可以获取特定的日志:
-log_files <Log File Name>: 使用ALL或者*匹配所有日志-log_files_pattern <Log File Pattern>: 正则表达式
- 可以显示日志文件的部分内容:
-size: 输出日志的最初或最终的字节数-size_limit_mb: 限制最大输出的日志大小
- 可以使用
-out <local directory>将日志下载到特定的位置 - 使用
yarn logs -help查看更多信息
RM v1 UI 与 JHS
通过RM的v1 UI访问日志往往不是很方便,它实际上是重定向到JHS的UI。对于任意的容器,使用下面的 URL 模板来访问 RM v1 UI,必须提供两次 containerId 参数:
1 | http://JHS-node:<JHS port>/jobhistory/logs/<node>:port/<container id>/<container id>/<user> |
该地址通过JHS的web应用路由,最终使用日志聚合控制器实例来获取日志文件。
对于已完成的应用,在RM UI的 All applications 选项卡上,用户单击应用的 ID,这将重定向到 Application Overview 页面。在这个页面上,底部有一个链接(logs),重定向到JHS的页面,显示AM的日志。如果需要其他容器的日志,用户必须用请求的容器ID重写URL。
对于正在运行的应用,JHS会显示正在运行的容器的链接。可以通过点击 All applications 页面上的应用ID来访问这些链接,然后跟随链接到应用attempt,在那里可以找到运行中的容器列表。对于这些容器,链接会显示来自JHS的页面,但它最终会将请求重定向到容器当前正在运行的节点上。
RM v2 UI
与旧版的UI相比,v2 UI能够显示已完成应用的任意容器。默认情况下,它使用JHS来获取应用的元数据(用于日志聚合文件控制器的 ContainerLogsRequest)。如果UI不能连接到JHS,它将尝试从 Timeline Server 获得这些数据。它使用REST API来获取元数据和显示日志。
在3.3.0版本之前,用户还应该有一个工作的 Timeline Server ,因为v2 UI使用AHS或ATS来获取应用相关的数据。
REST API
多个YARN守护进程提供了REST API端点,用于获取日志聚合相关数据。这些端点在统一之前有类似的实现(见YARN-10025的LogServlet改进):
- Job History Server (
/ws/v1/history) - Node Manager (
/ws/v1/node) - Application History Server (
/ws/v1/applicationhistory) - Application Timeline Server (
/ws/v1/applicationlog)
几个重要的端点如下:
/containers/{containerid}/logs: 返回有关特定容器的日志的数据。该输出以表格的形式显示在日志CLI中。如果在NM上,则需要容器仍然在该节点上运行。/containerlogs/{containerid}/{filename}: 返回日志文件的内容。如果容器仍在该节点上运行,JHS、AHS和ATS将重定向到NM。/containers/{containerid}/logs/{filename}: 这是以前端点的旧路径,它将重定向到以前的端点。/aggregatedlogs: 返回特定容器的日志数据。它的附加功能是提供查询参数支持,例如/aggregatedlogs?appattemptid=appattempt_1592201557896_0002_000001。支持过滤应用、应用尝试和容器ID。